Сдать экзамен или поставить полученную оценку в зачетку/ведомость можно приехав в ИСП РАН. Перед этим рекомендую написать мне письмо и договориться о времени. В университете я буду скорее всего только в январе.
Денис.
Сдать экзамен или поставить полученную оценку в зачетку/ведомость можно приехав в ИСП РАН. Перед этим рекомендую написать мне письмо и договориться о времени. В университете я буду скорее всего только в январе.
Денис.
Выкладываю новые билеты к экзамену (осенний семестр 2013).
В 21-м слайде лекции 3 (Языковые модели) была неправильная информация. Вопрос вызывала формула 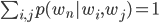 .
.
Эта формула относится к оценки вероятности N-граммы на основе метода максимального правдоподобия и означает вероятность события, что слово 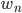 встретилось в одном из всех возможных контекстах, в которых оно встречалось. То есть выполняется всегда.
встретилось в одном из всех возможных контекстах, в которых оно встречалось. То есть выполняется всегда.
В случае, когда применяется сглаживание откатом к модели меньшего порядка (вероятность n-граммы равна 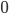 ) необходимо сбалансировать вероятности всех n-грамм, так чтобы сумма вероятностей заданного слова во всех контекстах (в том числе и меньших порядков) была равна
) необходимо сбалансировать вероятности всех n-грамм, так чтобы сумма вероятностей заданного слова во всех контекстах (в том числе и меньших порядков) была равна  .
.
В разделе 6.4 основного учебника приводится подробный вывод коэффициента  . Всем интересующимся рекомендую заглянуть туда.
. Всем интересующимся рекомендую заглянуть туда.
PS. Спасибо внимательным студентам за вопрос. Слайд в лекциях исправлен.
| Лекция | Слайды |
|---|---|
| Лекция 1. Задачи обработки текстов | lecture1-2012.pdf |
| Лекция 2. Регулярные выражения и конечные автоматы | lecture2-2012.pdf |
| Лекция 3. Методы поиска словосочетаний | lecture3-2012.pdf |
| Лекция 4. Языковые модели и задача определения частей речи | lecture4-2012.pdf |
| Лекция 5. Контекстно-свободные грамматики и синтаксический анализ | lecture5-2012.pdf |
| Лекция 6. Статистические методы синтаксического анализа | lecture6-2012.pdf |
| Лекция 7. Лексическая семантика | lecture7-2012.pdf |
| Лекция 8. Вопросно-ответные системы и автоматическое реферирование | lecture8-2012.pdf |
| Лекция 9. Машинный перевод | lecture9-2012.pdf |
Первое занятие состоится в аудитории 612 в пятницу 4-го октября в 18.00. На вводной лекции будут рассмотрены классические задачи обработки текстов и типичные проблемы, возникающие при решении этих задач. Также будут обсуждаться некоторые организационные моменты.
Приглашаются все, кто хочет понять, о чем будет спецкурс, и что нужно для того чтобы успешно его завершить.
Итак, экзамен прошел, время подвести итоги.
На курс зарегистрировались 40 человек. Успешно завершили практическое задание и были допущены к экзамену 26 человек. Результаты экзамена:

По результатам практической части выкладываю top 9 лучших решений:
Экзамен состоится 14 декабря в аудитории П-6. Начало в 18.00.
Билеты к экзамену можно скачать по ссылке.
Доступны слайды седьмой лекции. На лекции обсуждаются
Основные понятия лексической семантики
Вычислительная семантика
Готовы слайды к шестой лекции. На лекции рассматриваются проблема синтаксической многозначности и статистические алгоритмы синтаксического анализа.